
Abstract
A common explanation for Electronic Voice Phenomena (EVP) is that the reported utterances are mundane sounds mistaken as voice forming words. This report describes three online listening trials that were conducted to determine whether or not website visitors can correctly identify words that are thought to be EVP by listening to unmarked sound files.
A second consideration is that it is a popular wisdom amongst EVP practitioners that one must learn to correctly understand EVP. A variety of approaches were tried to test this theory, including polling experienced listeners, using questions in an attempt to assess interest and predisposition to believe in EVP and asking participants to indicate experience in hearing examples. Analysis of the trials is included, along with an assessment of the reliability of the results.
When the total number of words correctly recognized for the three trials is compared to the possible number, the overall percent Recognized words (%Rw) is 25.2%, indicating that at least some EVP do constitute recognizable words.
Introduction
Electronic Voice Phenomena (EVP) is defined as voices found in recording media, for the presence of which, there is no apparent physical explanation. Lacking a physical cause for the utterances, the working hypothesis most popularly proposed to explain them is the Survival Hypothesis.1 Specifically, that a person is a nonphysical Self (sometimes referred to as the personality, point of view or consciousness) in a symbiotic relationship with a physical body, and at the moment of death of the physical body, the Self is free to “return” to its more natural nonphysical environment. The hypothesis further holds that there is a nonphysical aspect of reality in which the survived Self exists, and from which it is able to communicate “back into” the physical via the mediumship of a still physical person, either technology augmented or via the human channel.
Alternative explanations for EVP which depend on physical principles include naturally occurring sounds mistaken as voice, real but mundane voices in the environment (voice contamination), radio frequency contamination, technology artifacts and sound file processing errors (processing artifacts). Super-PSI explanations that do not depend on the Survival Hypothesis include “echoes of the past” from residual mental energy that is stored in an as yet undefined quantum field and the recording of thoughts of the living. An emerging theory is that the practitioner and/or an interested observer creates an expected reality (experimental result), which is then mistaken as a trans-etheric influence.
Analysis of these theories is beyond the scope of this paper but they are briefly addressed in the Association TransCommunication (ATransC) article, ITC White Paper.2 This paper is written with the assumption that EVP exist but how or why they exist is not addressed, nor is the question of their paranormality other than in the context of what is known about their nature.
Statement of Question 1: That EVP are ordinary sounds mistaken as voice is described as “pareidolia,” which is defined as “the erroneous or fanciful perception of a pattern or meaning in something that is actually ambiguous or random.”3 There can be little doubt that people do sometimes inappropriately assign meaning, but by definition, EVP is not pareidolia; however, for this statement to be true, then words reported in EVP must be distinguishable as words. Further, there should be some measure of agreement amongst listeners as to what is said.
Question 1: Can words in EVP be correctly identified by a website visitor without guidance.
Answer Format: A consistent measure of correctly identified words (Recognized words = Rw) greater than zero would indicate that at least some parts of the example EVP are real words.
Statement of Question 2: EVP are not formed with a biological system, but are formed in novel ways that produce sounds that represent words; they are simulated words. The words are often so arranged that they are not recognized as language without prior training. The assumption of these trials is that website visitors are “average” people ranging in experience listening to EVP from novice to expert. If the result of Question one is affirmative, then there should be a measurable difference in %Rw between novice listeners and experienced listeners.
Question 2: Is there an increase of %Rw with increased experience hearing EVP examples?
Answer Format: People who are experienced in listening to EVP should produce measurably higher %Rw.
Factors Influencing How EVP is Understood
The words of EVP should not be thought of as being formed by a biological system. Analysis has shown that they are simulations of words, and because of an often imperfect simulation, they are not understood in the same way as the same words spoken by a physical person. Because of this, some experienced practitioners have speculated that correctly hearing EVP is a learned ability.
Unusual Arrangement of Formants
 It is fairly standard practice to classify EVP examples according to how easily they are correctly understood. A Class A voice can be heard and understood over a speaker by most people. A Class B voice can be heard over a speaker, but not everyone will agree as to what is said. A Class C voice is difficult to understand under any condition. An utterance may have one or two clearly understood words. Loud does not equal Class A. The majority of examples are Class C, and probably only one in several hundred are Class A.
It is fairly standard practice to classify EVP examples according to how easily they are correctly understood. A Class A voice can be heard and understood over a speaker by most people. A Class B voice can be heard over a speaker, but not everyone will agree as to what is said. A Class C voice is difficult to understand under any condition. An utterance may have one or two clearly understood words. Loud does not equal Class A. The majority of examples are Class C, and probably only one in several hundred are Class A.
The problem with this classification system is the assumption that all listeners have the same ability to understand the words in EVP. However, experience indicates that hearing the utterances is something of a learned ability and understanding them is not unlike learning a new language. That is, the words in EVP are formed in novel ways that often confound an untrained listener. This observation lacks the support of clinical studies, but there are a number of studies and learned opinions which may provide reference for further study.
Novel Voice Formation
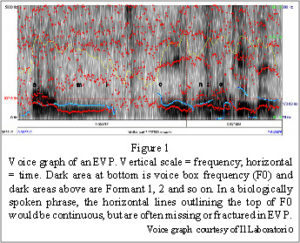
Analysis of the voices by the Italian research group, Il Laboratorio4, indicates that the fundamental voice frequency is often distorted or missing in the utterances, as shown in Figure 1.
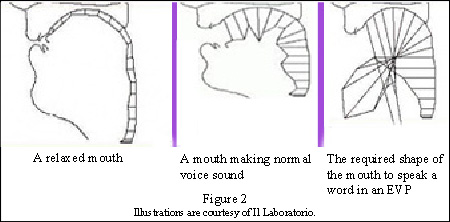 Figure 2 includes illustrations created by forensic-quality software used by Daniele Gullà at Il Laboratorio. The software creates illustrations showing probable shape of a mouth when speaking particular sounds. The software will sometimes fail to properly determine the shape of the mouth necessary to form some of the sounds in EVP.
Figure 2 includes illustrations created by forensic-quality software used by Daniele Gullà at Il Laboratorio. The software creates illustrations showing probable shape of a mouth when speaking particular sounds. The software will sometimes fail to properly determine the shape of the mouth necessary to form some of the sounds in EVP.
An important characteristic of EVP is that they are energy limited; they are typically only a few words and appear as packets of audio energy with about the same average power in the waveform. This is a generalization, but examples are often encountered in which short utterances (one or two words) are relatively loud while longer ones (four or five) tend to be a little quieter or loud with a trailing-off or garbled enunciation at the end. Extraordinarily long utterances tend to be delivered as concatenated packets of words with evident pauses between packets, as if energy is being gathered between efforts. In some cases, different speakers will finish a concatenated utterance, or several speakers might speak in unison, as if sharing energy to “get through.”
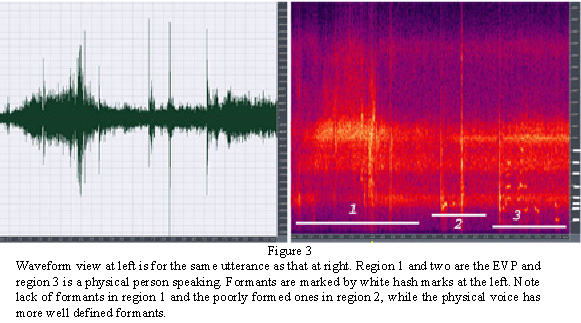 Figure 3 provides an example of an EVP which is delivered in two packets with an evident pause between packets. At left is the waveform view of the same example shown at the right as a spectral view. The first packet (region 1 in the spectral view) is most easily understood, while the second (region 2) seems to be better enunciated, but is not as easily understood. The second may be a different person attempting to assist the speaker, or alternatively, the single speaker may have achieved more control over the “circuit.”
Figure 3 provides an example of an EVP which is delivered in two packets with an evident pause between packets. At left is the waveform view of the same example shown at the right as a spectral view. The first packet (region 1 in the spectral view) is most easily understood, while the second (region 2) seems to be better enunciated, but is not as easily understood. The second may be a different person attempting to assist the speaker, or alternatively, the single speaker may have achieved more control over the “circuit.”
Region 3 (right end) is a physical person speaking. The EVP would be characterized overall as a Class C. but Region 1 would be considered a Class B. If you look at the spectral view of the same sound file, you will see that area 3 shows definite formant formation while area 1 does not and area 2 is partially defined. The formant levels are indicated by the white hash marks on the right side of the frame. Area 1 is thought to say, “I’m fine” while area 2 is thought to say “love you mom.” I can make out the “I’m fine” quite well, but not the area 2 and certainly not the woman’s quiet voice, even though you see the voice is well defined.
Parenthetically, another point illustrated in Figure 3 is that, when there are clearly defined formants in an EVP, it is possible to put the signal through a low pass filter and take out some of the formants. Doing so usually does not hurt physical speech, but it can change how an EVP is understood. Also, as is noted above, noise reduction tools (not filters) use a sample of the waveform to build a profile, which is then used to selectively remove those frequencies by amplitude. If the utterance is formed from the noise, then in some cases, the utterance is removed or is altered to be interpreted as having a different meaning. So yes, it is possible to cause processing artifacts with inappropriate processing of the sound file, although such processing does not produce an utterance unless it is someone trying to find voice in a near-zero-level, flat-line waveform. In that case, it is possible to make radio-frequency contamination audible.
Hearing with Templates
Alexander MacRae has proposed a possible explanation for why some people have difficulty hearing and understanding EVP.8 In part, he explains that:
- My article on hearing with templates makes the point that what we hear is not necessarily the same as what we are listening to. And then the point is made that templates are used in all recognition processes, whether recognizing phonemes (elements of words), patterns of phonemes which are words or patterns of words which are phrases. What you actually “hear” is the template. You can also hear all the other noises that are part of what you are listening to, but what you actually “hear” is the template that best fits the sound pattern.
- If you listen to a sequence of phonemes that you have never heard before, for instance, “Gelarumipalat,” which is not a word in the languages that you understand, which does not have Latin, Greek or Germanic roots, what you will hear is a sequence of phonemes, pure and simple. If you listen to a recognized sequence of phonemes such as “angry,” you hear a word. And if you listen to a sequence of known words in a recognized sequence such as, “I am so angry!” what you “hear” is a meaning.
- What you listen to and what you hear can be different things. There has to be a distinction, therefore, between EVP that is so good it is close to normal speech in good listening conditions which I call A-type EVP, and EVP that is not that good which I will call that B-type EVP. They are both EVP but they have different behavioral characteristics.
- With B-type EVP:
- Different people may hear different things;
- What is heard using headphones may be different from what is heard using a speaker;
- What is heard when one is told what it is, may be different from what one heard before being told what it is; and,
- What one hears at one time may be different from what one hears at another time.”
- The point is that the EVP researchers are identifying important reasons why EVP are not heard as normal speech. Novel voice formation and missing timing cues that confound the mind are just two of the reasons an average person might think that an example of EVP is just noise, or at best, gibberish. If known problems of missing context, noise contamination and utterances that are spoken too softly or too fast are considered, then there begins to be a case for treating hearing and understanding EVP as a learned ability, not very different than learning a new language.
Listener Expectation
As it applies to psi phenomena, the experimenter effect refers to the influence a “believer” has on the outcome of a process. The hypothesis is that, if the experimenter expects a positive result, it is possible that he or she might psychically facilitate that result. The reverse is true of those who are not “believers.” If there is a psi aspect of EVP, then this same hypothesis should be considered.
The experimenter effect suggests that the person participating in the listening trials might be an unreliable listener because of a predisposition to believe or not believe.
- Agnosia: Loss of the ability to interpret sensory stimuli, such as sounds or images. (American Heritage Dictionary). Agnosia was once considered a rare condition, but since the work with inattention blindness, it has become clear that it is much more common than previously thought. An audio form of agnosia is also recognized, and what might be referred to as incredulity blindness should be considered in the analysis of listener ability to hear EVP. That is:
- Incredulity blindness: A category of inattentional agnosia or inattentional blindness, in which an audio or visual example of a phenomenon is not experienced because it is so foreign to a person’s worldview. There are at least two forms of the experimenter effect. One is the difference in experimental results collected by “believers” and “skeptics.” The second is due to the difference in results reported between a “believer” and a “skeptics.”
Effective Listening Technique
Website visitors volunteer to participate in the listening trials, but do not necessarily agree to follow the recommended procedure for listening to an example. As suggested in the introduction to the examples “…an excellent technique for examining a possible utterance is to select the suspected wave form and listen to it many times. If words are present to be understood, the listener’s mind will sometimes, eventually recognize them.” They are also asked to use headphones, rather than listening via speakers.
This technique is used with an audio management program such as Audition, or the open source, Audacity. Most people experienced with EVP use a similar program, and as is shown in Figure 3, variations in the waveform are suggestive of utterances, so it is easy to select one pulse of the waveform and listen to it many times using the “Loop” feature. Once a word “emerges” into my awareness, it is easy to hear it later when listening to the entire file. In effect, the person learns how to understand words as formed by that communicator.
Experimental Protocol
As of July, 2007, the Association TransCommunication (formally AA-EVP) website received an average of fifteen hundred unique visitors a day, making it an ideal platform for conducting online EVP listening experiments. Also, the site ranks high in search engines, assuring that both people seriously interested in EVP and the idly curious will find the page hosting the experiment.
 The basic protocol utilizes a web page inviting website visitors to listen to audio files labeled with just the word, “Example” and a number. Visitors were asked to type what they heard in an unlabeled text field. This information was sent to an email address and also to a database on the website server.
The basic protocol utilizes a web page inviting website visitors to listen to audio files labeled with just the word, “Example” and a number. Visitors were asked to type what they heard in an unlabeled text field. This information was sent to an email address and also to a database on the website server.
A conscious effort was made to allow very little tolerance for what was considered a correct interpretation of the examples, and other than as noted below “almost right” words were generally not accepted as correct. The number of words contained in the examples ranged from one to seven words and each word was counted as a possible hit or miss. Allowance was given for the way words are commonly heard or reported. For instance, “Shut up” was counted as one word, because that is the way it is commonly heard, “spirit” and “spirits” were equally accepted, but “I’m” was not accepted when it was supposed to be “We’re.”
The resulting database was manually tallied based on the number of words correctly reported for each example by each participant. Data is not available for how likely any one word in the English language is to be guessed in any single attempt. However, it is predictable that some words are more likely to be guessed than are others, especially if the participant has previously listening to EVP examples on the Internet. For instance, words like “the” and “is” are commonly found in phrases, as are “I,” “I’m” and “we.” Names are often in EVP examples, and some names are more common than others. For these reasons, no effort was made to evaluate the responses based on deviation from chance guessing of words. Instead, a straightforward count was made to establish average percentage of correctly reported words, compared to the total number in the example multiplied by the number of entries.
Normalizing Quality of Examples
Some examples are simply harder to understand, and so, a means of predicting how hard an example is to understand would be helpful for the analysis of the results. In an attempt to establish this measure, participants were asked questions designed to determine their experience in hearing EVP or inclination to believe in their validity as natural phenomena. The intention was to find a way to say that this participant has, say a skill level of five on a scale of one (beginner) to ten (expert), and the %Rw for the person was n%. Then to compare all entries for that example versus average skill level to establish a quality index for the example. Overall, this was not successful, although the data is provided and comments have been made for each trial.
Trial 1
Five examples thought to be Class A were used. In an effort to avoid recognition by participants, they were selected because they were not widely used. Participants were asked to select from the following options:
Please select one or more the following descriptions that best describes you:
- I have studied EVP and believe they are caused by discarnate people.
- I have studied EVP and believe that there is a physical explanation for them.
- I consider myself a skeptical person when it comes to the paranormal.
- I have been academically trained in the sciences.
- I am academically trained but not in the sciences.
There was a problem in determining the number of correctly identified words as compared to the participant’s background because participants were able to select more than one response. While the raw data contains this information, it was generalized as:
- I have studied EVP and believe they are caused by discarnate people.
- I consider myself a skeptical person when it comes to the paranormal.
- I consider myself a skeptical person when it comes to the paranormal and I am an academically trained scientist
- I have been academically trained in the sciences.
- I am academically trained but not in the sciences.
- No background marked.
The responses were stored on the internet and also delivered via email to my computer. (The raw data is available for analysis on request.) In the first experiment, a response came as (actual-typical):
Example 1: shut up vicki good job vicki
Example 2: we can’t go in the
Example 3: the voice is mine
Example 4: hi ,mom
Example 5: big speech from the mommy
Studied evp and believes evp:
Studied evp and believes physical:
Skeptical: Skeptical
Scientist: Trained Scientist
Layperson:
Remote Name: nn.nnn.nn.nn
Remote User:
Date: 08 February, 2007
Time: 11:59 AM
After one hundred “qualified” responses, the experiment was stopped because of the time required for processing the results and because there was an almost exponential increase in attempts to sabotage the experiment with misleading responses. Judging by the “Remote Name” (IP address), after indicating they were skeptical, some were coming back a second time, saying they had studied EVP and believed it to be phenomenal and then typing random characters in the response field. All duplicated responses were discarded.
“Qualified” respondent actually wrote a response for at least one example, and the response was something other than random characters. Blank entries for individual examples were counted as a “miss” as long as there was some form of response for at least one example; however, entries with no attempted word identification for all five examples were discarded.
The five examples included nineteen words. Example 1 sounds as if it was “Shutup Viki” repeated twice, rather than the actual “Shutup Vicki, just shutup Vicki.” Many gave the correct first half and the assumption was made that the second half was mistaken as a repeat. (Repeating the example in the same recording is a common practice.) As previously noted, “shut up” was counted as one word because that is pretty much the way it is heard. Thus, a “shutup Viki” response was counted as four words because we feel the participant assumed a repeat. Other decisions made for judging correct word identification included:
“Were” is okay for “Where’s”
“Sticky,” “Dickey” or “Becky” was not counted for “Viki” but “kiki” was
“Than” is accepted as “thanks” but “Think” was not accepted
“Hay” was accepted for “Hi”
“Mommy” was not accepted for “money”
“Bob” was not accepted for “mom”
Trial 1 Results
There were ninety-six “qualified” responses resulting in a possible 1,824 words. There were 612 correctly recognized words (Rw) or ”’overall %Rw = 33.6%”’. Based on how participants answered the profile questions:
- I have studied EVP and believe they are caused by discarnate people.
%Rw = 40.9% (35.4% of participants (34 people))
- I consider myself a skeptical person when it comes to the paranormal.
%Rw = 28.0% (32.3% of participants (31 people))
- I consider myself a skeptical person when it comes to the paranormal and I am an academically trained scientist.
%Rw = 20.0% (5.2% of participants (5 people))
- I have been academically trained in the sciences.
%Rw = 27.4% (5.2% of participants (5 people))
- I am academically trained but not in the sciences.
%Rw = 28.3% (13.5% of the participants (13 people))
- No background marked.
%Rw = 38.2% (8.3% of the participants (8 people))
“Shutup Vicki just shutup Vicki” recorded by Viki Talbott (5 words).
Possible 480 words (96 x 5) with 247 words correctly identified or %w = 51.5%.
“We keep looking for peace” recorded by Lisa Butler (5 words).
Possible 480 words (96 x 5) with 69 words correctly identified or ”’%Rw = 14.4%”’.
“Where’s mom” recorded by Martha Copeland (2 words).
Possible 192 (96 x 2) words with 85 words correctly identified or ”’%Rw = 44.3%”’.
“Hi mom” recorded by Teri Dabber (2 words).
Possible 192 words (96 x 2) with 84 words correctly identified or ”’%Rw = 43.8%”’.
“Thanks, thanks for the money” recorded by Vicki Talbott (5 words).
Possible 480 words(96 x 5) with 127 words correctly identified or ”’%Rw = 26.5%”’.
Trial 2
A second listening trial was conducted in an effort to better establish an average for %Rw and to determine whether or not it was possible to relate ability to hear to background. Five examples thought to be Class A were used, along with one example spoken by a physical person. Once again, they were selected because they were not widely used, in an effort to avoid recognition by participants.
Background information: The background information participants were asked to provide was different from Trial 1 in an effort to find a more useful way to profile the participants. They were asked:
Identifying the mundane utterance: Near the end of the trial, participants were told that one example was mundane and participants were ask to use a provided check-boxes to indicate which one they thought was mundane.
Testing for response fatigue: The number of correctly recognized words (Rw) for example six was unexpectedly low so examples one and six were reversed during the trial to see if the Rw world changed. Such a change in Rw would seem to indicate that participants were experiencing “fatigue” in trying to listen to so many examples.
The EVP, “It’s Jamie” had a %Rw of 56.6% when it was Example 1 and a %Rw of 62.3% when it was Example 6. The differential is 5.7% with a gain for being the last example.
The EVP, “I survived” had a %Rw of 22.5% when it was Example 1 and a %Rw of 27.4% when it was Example 6. The differential is 4.9% with a gain for being the last example
Response format: As in Trial 1, the responses were stored on the internet and also delivered via email to my computer. (The raw data is available for analysis on request.) A response came as:
Normal Speech: Yes 4
Example 1: jeremy
Example 2: im flying
Example 3: we come to get roxanne
Example 4: this feels weird
Example 5: you’re crazy
Example 6: im in your barn
Education:
Subject of education:
Background in evp: Have studied a little
Opinion about evp: May provide proof of survival after physical death
Spam control: 2
B1: Submit
Remote Name: nn.nn.nnn.nn
Remote User:
Date: 07 July, 2007
Time: 05:52 PM
The same rules were applied to grading correctly reported words in Trail 2 as was used in Trial 1. For instance:
- Any word that began with a “J” and ended with a “m” and a “ie” ending, such as “y” or “e.”
- Not accepted: Words like “Jane” and “Jenny.”
- “I’m” was not accepted for “I”
- “Survive” was accepted for “survived”
Trial 2 Results
The mundane example “Will you tell me the grump’s name?” was not counted in the tally. The maximum number of responses for the remaining five was 217, but as few as 184 were counted in one example because some participants made no entry. Overall, there was a possibility of 2,844 recognized words. 855 words were recognized for an average of 30.1% (Overall %Rw = 31.0)
“It’s Jamie” recorded by Ginny Sawyer (2 words).
Possible 434 words (217 x 2). 249 words were correctly identified or %Rw = 57.4%
“It’s Frank” recorded by Karen Mossey (2 words).
Possible 426 words (213 x 2). 207 words were correctly identified or %Rw = 48.6%
“Will you tell me the grump’s name?” recorded by Martha Copeland (7 words). This is a mundane voice spoken by Martha Copeland.
Possible 1365 words (195 x 7). 449 words were correctly identified or %Rw = 32.9%
“We’re still in spirit” recorded by Vicki Talbott (4 words).
Possible 832 words (208 x 4). 191 words were correctly identified or %Rw = 22.9%
“Tell her it’s Satan” recorded by Martha Copeland (4 words).
Possible 736 words (184 x 4). 102 words were correctly identified or %Rw = 13.9%
“I survived” recorded by Martha Copeland (2 words).
Possible 416 words (208 x 2). 106 words were correctly identified or %Rw = 25.5%
Trial 3
Trial 3 was an attempt to determine whether or not it was reasonable to ask participants to estimate their previous experience in listening to EVP examples. Participants were also asked to identify any organization with which they were affiliated. This question was intended to permit identification of a control group, such as a teacher’s students or members of the ATransC. All examples were recorded using an audio recorder as transform EVP (transformation of available noise into words), except for one recorded using the radio-sweep method as an opportunistic EVP (just in time sounds selected to form words). See Locating EVP formation and detecting false positives. (Radio-sweep is accomplished with a modified radio popularly known as “ghost boxes” or “spirit boxes.”)
Response format: As in the other trials, the responses were stored on the internet and also delivered via email to my computer. (The raw data is available for analysis on request.) A response came as:
Example 1: NO ONES HELD ME
Example 2: ROB IS PEEKING CAN HE HELP THAT
Example 3: THIS IS SOOO DIFFICULT
Example 4: HEAVENS THE BEST
Example 5: YOU SHOULD MOTHER _ _ _ _ A
Example 6: HELLO
Posit science results: 7.25B
Organization: AAEVP
Experience: 8
Spam control: 2
B1: Submit
Remote Name:
Remote User: xx.xxx.x.xxx
Date: 02 February, 2008
Time: 08:08 PM
IP addresses were examined and multiple entries from the same IP were deleted, except in the instances in which the reported words were identical. In identical, duplicated entries, only one was counted; the assumption being that the duplicate was accidental.
The same rules were applied to grading correctly reported words as was used in the other trials, so that:
- Death was accepted for dead
- Catherine was accepted for Cathy but not captain
- McTaulk not accepted for talking
- Shaw, Sha, Shraw, Shah and Saul were accepted for Shawn but not Sean, Sal or Saw
- Talk was accepted for Talking
- Help was accepted for helping
- Death was accepted for dead
- Merrill was accepted for Marilyn
- Words like Kevin not accepted for Cathy
- Help me was not accepted for Helping but was given one word for help
- Weak was accepted for Week but not speak
Trial 3 Results
results of your test below, but this is optional.197 entries were accepted for a possible 4,334 words to be recognized. 804 words were correctly recognized for an average of 18.6% (Overall %Rw = 18.6%).
-
“Joeys helping” Recorded by Margaret Downey. 2 words, had a possible 394 possible (2 X 197), 121 words were correctly identified or %Rw = 30.7%
42 responses were “Someone help me” or close variation of this.
-
“Not this week. We can help” recorded by Margaret Downey. 7 words (Radio Sweep) had a possible 1,379 possible (6 X 197), 34 words were correctly identified or %Rw = 2.5%
“Have to speak” or “Do I have to speak,” was a common response. There were 100 “speak” responses, and if “speak” had been accepted for “week,” %Rw would be %Rw = 9.7%
-
“This is Shawn talking” recorded by Margaret Downey. 4 words, had a possible 788 possible (4 X 197), 343 words were correctly identified or %Rw = 43.5%
7 responses were “This is so difficult” and 6 were “This is from the top.” “This is” accounted for most of the hits for this example.
-
“Cathy, you’re dead” recorded by Margaret Downey. 3 words, had a possible 591 possible (3 X 197), 216 words were correctly identified or %Rw = 36.6%
60 responses begin with “Kevin.”
-
“You should never step out” recorded by Lisa Butler. 5 words, had a possible 985 possible (5 X 197), 83 words were correctly identified or %Rw = 8.4%
40 responses began with “This is” and 20 began with “we should,” “said” or “shall.”
-
“Marilyn” recorded by Lisa Butler. 1 word, had a possible 197 possible (1 X 197), 7 words were correctly identified or %Rw = 3.6%
6 responses were “Hell,” 56 were “Hello,” 20 were “Help” and 16 “Sarah.”
Experience Hearing EVP vs. %Rw
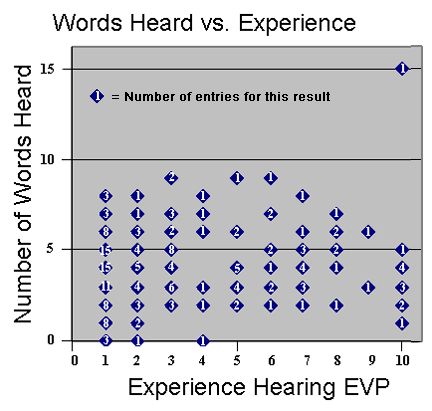 This plot shows the distribution of (self-reported) experience and %Rw. Each the number in each point represents the number of entries represented. The average experience level is about 3.6 with an average %Rw = 20.3% The two numbers for experience level 10 is without and with (second number) the single result of fifteen correctly recognized words. (The total numbers reported here deviates from the overall average because some people failed to indicate estimated experience.)
This plot shows the distribution of (self-reported) experience and %Rw. Each the number in each point represents the number of entries represented. The average experience level is about 3.6 with an average %Rw = 20.3% The two numbers for experience level 10 is without and with (second number) the single result of fifteen correctly recognized words. (The total numbers reported here deviates from the overall average because some people failed to indicate estimated experience.)
The graph does not include entries that did not offer an experience level.
If understanding EVP is a learned ability, then an improvement in %Rw should be seen with more experience. But as can be seen in the table below, the %Rw is almost flat. one possible explanation for the lack of improvement may be the human nature tendency to overestimate personal ability. It is difficult to know how much experience one has, or how “good” one has become in listening to EVP when interested people are so few and far in-between. For this question to be properly asked and answered, it appears that a standardized hearing and experience tests would need to be administered before the actual listening trials are conducted.
Posit Science Results
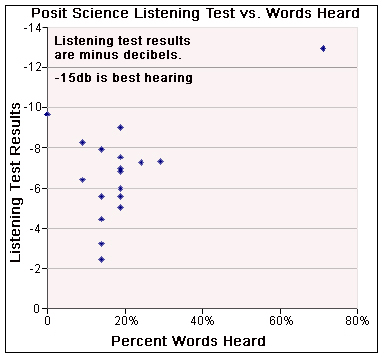 As a way to evaluate how well participants hear voice in noisy environments, we asked participants to take the Posit Science Speech in noise” hearing test (No longer available) You will be asked for the results of your test below, but this is optional.
As a way to evaluate how well participants hear voice in noisy environments, we asked participants to take the Posit Science Speech in noise” hearing test (No longer available) You will be asked for the results of your test below, but this is optional.
Nineteen people reported a Posit Science result. -15 is the best possible result. The average was -6.8 with an average %Rw = 19.4%. Overall, participants had a %Rw = 19.4%, indicating that hearing ability alone is not a major factor in the ability to understand EVP.
Discussion
Question 1 was to test the pareidolia hypothesis, and if %Rw was greater than zero, to establish parameters for how EVP are heard. Whether or not EVP are mundane sounds mistaken as voice should be able to be determined by whether or not sound files thought to be EVP can be heard to say what EVP experiments think they say. With an average percent recognized words or %Rw = 36% for Trial 1, %Rw = 30% for Trial 2 and %Rw = 18.6% for Trial 3. Based on total number of words recognized for all three trials, the overall average of %Rw = 25.2%, it seems clear that at least the examples used in this exercise are composed of sometimes intelligible words, and therefore, are not figments of an experimenter’s imagination.
Stats
3 trials
17 examples (One mundane voice and one radio sweep, the rest are transform EVP made with a plain old recorder.)
510 participants
9,002 possible words
2,7271 words correctly recognized.
25.2% Overall %Rw
Question 2 addressed the idea that EVP are formed in novel ways that produce sounds that represent words, and that the words are often so arranged that they are not recognized as language without prior training.
- In Trial 1, people who indicated that they have studied EVP scored a %Rw of 40.9% (34 people), as compared to 28.4% for the other participants combined (62 people). This is a difference of 12.5%
- In Trail 2, people who have recorded EVP had a %Rw of 33.0% (14 people) while the people indicating having no experience with EVP scored 21.9% (79 people) for a difference of 11.1%.
- In Trial 3, %Rw based tallied by self-reported experience levels was nearly flat from no experience to considerable experience.
The results of Trial 1 and 2 seem to indicate that learning does improve performance, which seems to support the hypothesis that one reason people new to EVP often report hearing EVP as just noise is that they have not learned to hear the utterances. However, participants were asked in Trial 3 to estimate their experience in hearing EVP, and for the most part, reported experience versus %Rw did not support the self-hypothesis that learning is required.
Cooperation of the Participants
During the first trial, the editors of Wikipedia active in the EVP article at the time were told that there was a trial under way. Directly after that, responses began to be received that were first marked as being from a skeptical person and then the same IP came back one or more times marked as being from a “believer.” The responses also changed from an apparent honest effort to hear the words to mere random typing or obviously wrong responses. This escalated so that it was necessary to discontinue the trial when the majority of responses were of this nature. Wikipedia is controlled by editors who are ideologically in line with and strong defenders of mainstream science.
Single responses cannot be excluded just because it seems that there was no honest effort to hear the words; however, when there is more than one entry for a single IP, all entries associated with that IP were discounted, even when their %Rw was high. A negative of this policy is that some IP addresses are associated with publicly accessed computers, such as in libraries and schools.
The one exception to discounting responses with duplicated IPs is when the response itself is both consecutive and identical, in which case it was assumed that a mechanical error occurred and the first response was retained while the second was discounted.
A second form of vandalism comes in the form of unreasonable interpretations of an example. In the waveform shown here, changes in amplitude corresponds with the utterance–first part anomalous and the last part mundane. An interpretation of what is said should have some correspondence with the number of amplitude pulses, especially as seen in the spectral view at the right. In other words, if the listener makes an effort to hear what is said, what is typed in the response field should at least approximate the number of sound pulses, even if the typed words are not correct. There were many responses containing far too many syllables to be seriously related to the example. Yet, it is necessary to count such responses because there is no overriding reason to assume vandalism. This does, however, reduce the usefulness of the overall trial.
Wrong Words Reported
An intriguing result of these trials is that the wrong word is sometimes more often reported than the right word. This was tracked in the third trial, and for instance, the last example is Marilyn, but it was identified as “hello” in 56 of the 197 responses. in Cathy, your dead, ‘Cathy” was understood as “Kevin” 60 times. If “Kevin” had been the correct response, the %Rw would have been better than 45% as opposed to the reported 36%.
In some cases, expectations of the listener might make a response more likely. For instance, in the Marilyn, “Sarah” was reported 16 times. Sarah Estep is the founder of the AA-EVP and has recently made her transition. “Help” was reported 20 times, and is another often reported EVP.
A phrase beginning with a “Ca” sound and one beginning with a “Ke” sound is close enough that people might hear one as the other. Participants are asked to use a headset and listen to the example several times, but in fact, one listening via computer speakers is probably best that can be expected. Audio performance varies amongst computers, as does environments, and it should be expected that listening errors will have a negative influence on %Rw.
Improving the Protocol
Normalizing the example: The best practice for grading how easily an EVP example will be understood is the Class A (easily heard), B (poorly heard, but hearable) and C (usually only heard by the practitioner) classification system. This is generally established by the practitioner and is only rarely determined by a listening panel. If the hypothesis that learning is required to understand EVP is correct, then the practitioner is not reliable as a standard for classification, nor is a listening panel.
The clarity of EVP examples varies considerably, and the ones used in these three trials are no exception. They were selected because they are considered Class A, but I have nearly twenty years of experience hearing EVP, and if there is a learning curve, I am at it top and clearly am not a reliable standard. On the other hand, I have also played examples for many people, and have a sense of what the average person can understand.
Another factor in determining the quality of an example is that, if listeners are routinely told what the example is thought to say, they will be more likely to hear the example as a Class A. This is true even when the example might actually be a poor Class B. This is related to the listener’s expectation. For instance, if the example is recorded in a cemetery, the listener is more apt to assume an utterance is dreadful if the person assumes “dead” people are stuck there.
Normalizing listener experience: How well qualified the listener is to correctly hear an utterance is a second issue for hearing trials. As is seen here, self-estimation of ability may not be reliable. Online trials depend on keeping the interest of the participant, and based on the results, the best circumstance might be academic. An instructor can request that students take the necessary screening tests, and then using an affiliation question in the online trials form to identify the control group. Ideally, participants would be given a hearing test using the computer with speakers or headphone that would be used for the trial. In addition, a set of questions could be developed to determine the participant’s experience hearing EVP based on a psychology-style aptitude test.
An Ideal Protocol
- EVP examples would be taken from a pool of previously screened examples. This screening would be accomplished by using this same protocol to establish a control listening panel, and based on the control group’s performance with examples, a set of examples that have been given a grade. Thus an example would have a factor based on control group score.
- Website visitors participating in a trial would include a listening test and a survey designed to provide a factor representing experience. Thus the participant would have a hearing score and a score for experience.
- Participants would then listen to a set of unmarked examples and type what they hear in an unmarked text field.
- Listening results would be graded based on hearing ability, experience and the quality factor of examples.
Conclusions
With the degree of normalization described above, it should be possible to use the online listening trial protocol to explore subjects such as how experience and/or personality traits influence ability to understand EVP. There is evidence of a cultural influence on how trans-etheric influences are experienced, and the online listening protocol may provide an important means of controlling the examination of these ideas.
EVP is just an objective form of trans-etheric influence, but it is also easily induced. Any time the conceptual world of the etheric is examined by people and their attendant observer influence, variables become involved that cannot be easily controlled. That is one of the reasons deviations from chance has become the primary approach for psi functioning studies. With the on-demand objective results of EVP research, such variables can potentially be controlled, and meaningful results can be expected.
References
- Butler, Tom, Survival Hypothesis Explained, ATransC, ethericstudies.org/trans-survival-hypothesis/
- Butler, Tom, EITC White paper, atransc.org/itc-white-paper/
- Word Spy: pareidolia.
- Interdisciplinary Laboratory for Biopsychocybernetics Research, Bologna, Italy (Il Laboratorio)
- Gullà, Daniele, Computer–Based Analysis of Supposed Paranormal Voice: The Question of Anomalies Detected and Speaker Identification, Interdisciplinary Laboratory for Biopsychocybernetics Research, Bologna, Italy, ATransC web site atransc.org/gulla-voice-analysis/
- Butler. Tom, Characteristic Test for EVP, Best Practices Development.
- “Formants,” Handbook For Acoustic Ecology, Cambridge Street Publishing, 1999.
- MacRae, Alexander, “Hearing with Templates,” Winter 2007 AA-EVP NewsJournal, atransc.org/theory/macrae-hearing_with_templates.htm
- Caroline Watt, Peter Ramakers, Journal of Parapsychology, The, Spring, 2003.
- Daniel J. Simons, Scholarpedia, 2007.
- Audition, Adobe Systems, Inc.
- Audacity, audacity.sourceforge.net/download/windows.
![]()